Note – Theory of Coding is also on YouTube! This post has a video. Watch it at – https://youtu.be/rOjPwES9R2k
Hoping you’ll support the YouTube channel just like you have greatly supported the website! 🙂
Hello people..! This is the first post of Dynamic Programming – Introduction and Fibonacci Numbers. In this post I will introduce you, to one of the most popular optimization techniques, the Dynamic Programming. Dynamic Programming is the way of solving very complex problems by breaking them into subproblems such that the optimal solutions of the subproblems can be used to construct the optimal solution to the main problem. Dynamic Programming was put forth by Richard Bellman, who is well known for his work, Bellman Ford Algorithm. The name Dynamic Programming is a very misleading name, he just gave it to hide the fact that he used a lot of mathematics to come up with Dynamic Programming.
Dynamic Programming such a general concept that is so often used in competitive programming, that you will see a dynamic programming problem every now and then. When you ask the people who solved the question, they say, “Oh! That’s a DP problem.”. And when you ask, “Wow! You know Dynamic Programming..?! When did you learn that…?”. They often say, “I didn’t learn it anywhere, it just struck my head..!”. I hear this from many people. Most of the all-time programmers solve DP problems with ease without formally learning Dynamic Programming. This is because, over the course of their programming experience, they found some defects in many algorithms, and the solution to correct them seemed rather too obvious to them. This is what Dynamic Programming corrects does too. It corrects the naive way of doing things such that we end up getting an optimal way of doing it. We will discuss the formal way of approaching a Dynamic Programming problem.
Elements of Dynamic Programming
There are two fundamental elements of Dynamic Programming –
- Optimal Substructure – We can apply Dynamic Programming to a problem if we are able to identify an optimal substructure for that problem. If a problem can be divided into sub problems such that, the optimal solutions to the sub problems can be used to construct the optimal solution of the main problem, then, the problem is said to exhibit an optimal sub structure. Generally, Greedy Algorithms are used to solve problems that exhibit optimal sub structure. Then, when do we use Dynamic Programming ? The next point answers that question.
- Memoisation – When the sub problems overlap, or, there is a vast repetition of the sub problems, then, it is better compute the optimal solution to the repetitive sub problem once, and then we store it. Similar to us writing notes on a memo table so that we can refer to it later. This is done so that whenever we need it again, we can lookup for the solution to the sub problem, which would save us the time of computing it again.
These two are the most fundamental elements of Dynamic Programming. If you can form the optimal substructure for the given problem and make sure that you don’t compute one sub problem again and again, then, you have made your code optimal in Dynamic Programming’s point-of-view…! Generally, the naive approaches to various problems have high complexity because we keep computing a sub problem again-and-again. Dynamic Programming exploits this fact. This can be very easily understood if we take up the example of computing the nth Fibonacci number. The code for the naive approach would be –
Is this approach efficient…? No..! It is a crazy approach..! Why..?! We all know that its complexity is exponential. Remember guys, for a code –
- O(1) is ideal.
- O(log N), logarithmic, is a fair compromise to being a constant.
- O(N), linear, is pretty fast.
- O(N log N) is okay.
- O(N2) is bad.
- And O(2N), exponential, will get you kicked out of the house..! 😛
But if we go deep into the algorithm we wrote above, we observe the reason why it is exponential in complexity. Try drawing the recursion tree of the above recursive algorithm. It should look something like this –
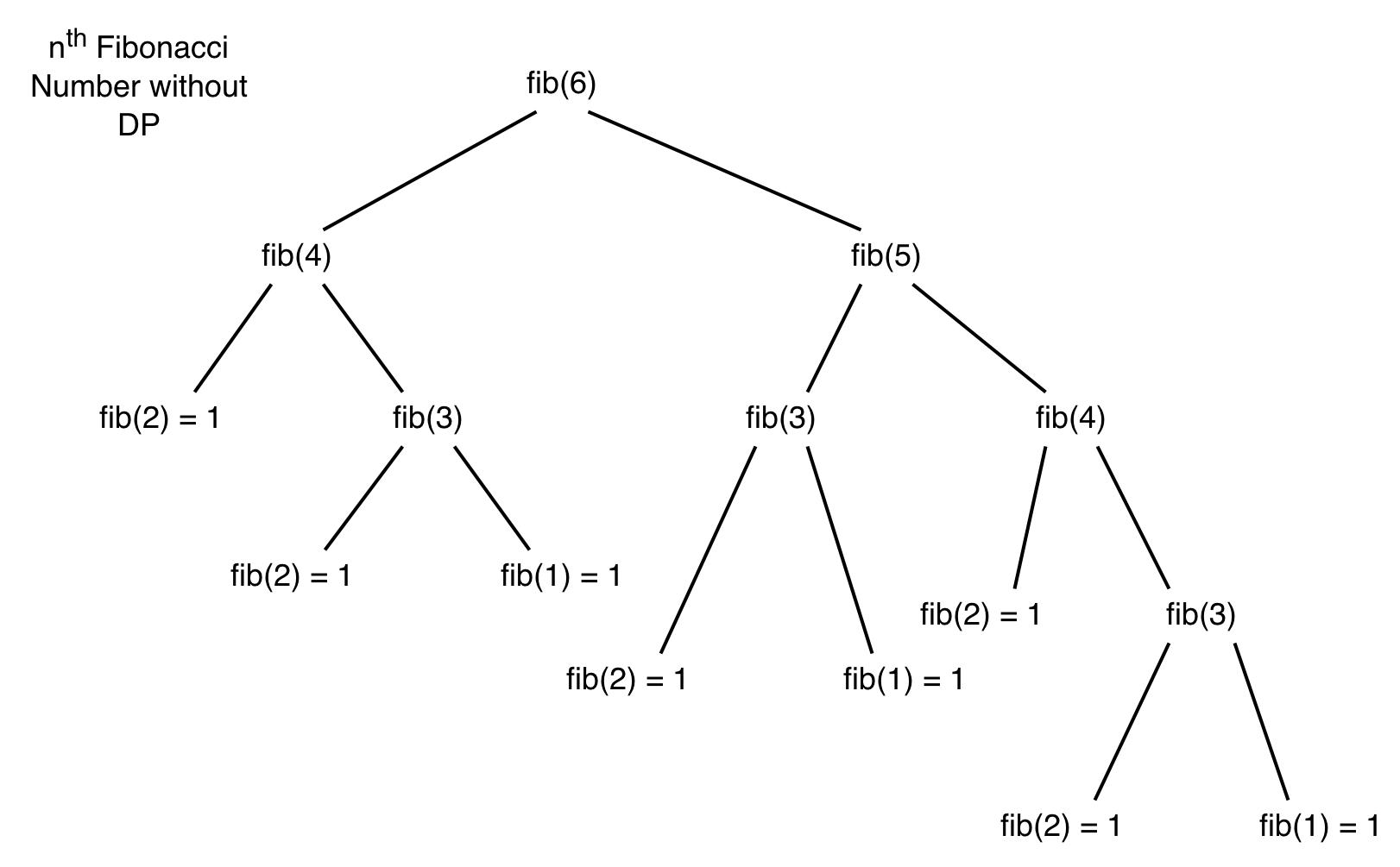
Observe closely…! The fib(4) sub-tree occurs twice and is exactly the same. The fib(3) sub-tree which occurs trice, is exactly the same everywhere. Clearly, we are doing the same thing again-and-again. What if we did it only once ? We could compute fib(i) only once and write it down somewhere so that it can be referred to later when we needed it again. If we compute fib(i) only once, our algorithm would have a complexity of O(N), which would be way better than exponential. This is what Memoisation does to an algorithm. It ensures that we don’t need to compute a sub problem again. Suppose we stored the value of fib(i) once we computed, we could save a lot of recursive calls. If we applied memoisation to the above recursive tree, it would look like –

The green tick marks indicate the value of recursive calls we would already know forehand. So, we would save all the recursive calls that would emerge from them. By the way, the word “Memoisation” is not a typo. It is “Memoisation” and not “Memorization”. It comes from the word “memo”, since we are writing down the values in a memo table so that we can look it up later.
Look up Table
For memoisation, we need a look up table. But, we should take care that the insert and find operations defined on this data structure do not take too much of time, otherwise, our algorithm might have the same worst case complexity as the naive one. So, what is the data structure that supports the fastest insert and search operations…? A Hash Table off course…! Hash table by chaining, with a decent hash function is one of the best options you have. But if you don’t have the time to create a hash table by chaining, or you don’t want to have so much of code in your algorithm, the next best thing you can think of should be a C++ STL Map, or a Multimap. Maps and Multimaps in C++’s STL Library are implemented using binary search trees. Which means that the insert and search operations defined on a map take O(log N) each. In most situations, O(log N) is a very good compromise for speed. This is because even if your ‘N’ is in the order of 106, log N, would be around 20, which has an almost negligible performance difference to that of O(1) time as far as 106 is concerned. So, using a map keeps you away from writing too much code, makes your program look neat and tidy. But, it is a compromise nonetheless. If your insert and search operations are way too high, prefer a Hash Table by Chaining. Python programmers can use a dictionary.
Bottom Up Approach
The correct way of solving the Fibonacci numbers is the “bottom-up” approach. As the name suggests, we do things “bottom-up”. What it means is that we compute the smallest sub problem first and then work our way up to progressively build the final solution. Take a look at the code below –
This function computes nth Fibonacci number in O(N) time and O(1) space complexity. It does it by keeping a track of TN – 1 and TN – 2 to compute TN. It does it in a bottom-up fashion, that is, we already know T1 and T2. Now it uses T1 and T2 to compute T3. Now, to compute T4, it will use the values that it already has, that is, it re-uses the solution to the sub problem, T3 to compute T4 (= T3 + T2). It goes on like this by using the solutions of the sub problems which it has already solved. Well, the function can compute only up to the 92nd Fibonacci number, beyond that can’t be put into a long long integer. But, this was the bottom-up approach. The bottom-up approach is slightly faster than the normal memoisation approach (or you could say “Top-to-Bottom approach”), because, it avoids function calls and performing operations on the look up table.
However, the fastest way to compute the nth Fibonacci number is not this. There is an O(log N) approach which based on the mathematical approximation formula –

The value computed by  is such that it very close to the nth Fibonacci number, so it can be rounded off to the nearest integer to get the nth Fibonacci number. The value
is such that it very close to the nth Fibonacci number, so it can be rounded off to the nearest integer to get the nth Fibonacci number. The value  is called phi, or “φ”, or the Golden Ratio. Now, the question is how to calculate
is called phi, or “φ”, or the Golden Ratio. Now, the question is how to calculate  in O(log N) time. We do this, by using Binary Exponentiation Technique, which works by Dynamic Programming…!
in O(log N) time. We do this, by using Binary Exponentiation Technique, which works by Dynamic Programming…!
Binary Exponentiation Technique
Binary Exponentiation Technique or Exponentiation by Squaring or simply Binary Exponentiation is used to compute positive integer powers of a number very quickly, in O(log N) time. This process basically, divides the job into two equally small sub problems, in this case, the sub problems are identical, so we solve it only once, recursively. This formula will make things clear –

This can be easily implemented by a recursive approach. The code would look like –
But this still isn’t an O(log N) approach. If you observe carefully, we are computing “BinaryExponentiation(x, n / 2)” twice at each step. We can improve the algorithm if we can memoise it. The Dynamic Programming version would be –
This is an O(log N) algorithm which gives  . If we substitute ‘x’ for φ and ‘n’ for (n + 1) and round it to the nearest integer, we would get the nth Fibonacci number. So, the call from main function would look like –
. If we substitute ‘x’ for φ and ‘n’ for (n + 1) and round it to the nearest integer, we would get the nth Fibonacci number. So, the call from main function would look like –
The additional 0.5 is to round it off to the nearest integer. It is a very clever way of rounding off floating point numbers. Give it a thought and try a few examples, I’m sure you’ll get it…! This is the O(log N) solution to calculate the nth Fibonacci number using Dynamic Programming.
Dynamic Programming VS Greedy Algorithms
A problem which can be solved by dynamic programming always seems that it can be solved by a greedy approach too. This is because if any problem exhibits optimal substructure property, it is said to be solvable by a greedy approach. So, when does Dynamic Programming come into the picture ? It is when the optimal sub problems overlap or repeat themselves. Then it becomes important to memoise the solutions to the sub problems to optimize our solution. But some times, the greedy approach doesn’t give the right answer.
Dynamic Programming VS Divide-and-Conquer
There is a subtle difference between the two flavors of algorithms. Both depend on the fact that dividing the main problem into sub problems and these local solutions can be used to construct a global solution. But, the sub problems in Divide-and-Conquer are disjoint in nature, that is, one sub problem has got nothing to do with the other. Where as, in Dynamic Programming, the sub problems are inter-dependent and they often overlap with one another. Its okay if you don’t understand this difference straight away, it will be more clear when we will finish our discussion about Dynamic Programming’s limitations.
Dynamic Programming as “Careful Brute Force”
Most problems of Dynamic Programming actually don’t contain any genius logics. Well, look at the above example. We didn’t do anything super intelligent. We just looked at all the different possibilities, which is nothing more than a brute force kind-off approach. But, we did this “carefully”…! We ensured that we never did the same exact thing twice in our algorithm and the algorithm ran perfectly. What really happens in a brute force approach is that we tend to compute the same things again-and-again. By using memoisation, we can turn it into an efficient algorithm. So, henceforth, whenever you think of a brute force algorithm, think of what you are doing again-and-again, then, you’ll know if the given problem is actually a Dynamic Programming problem or not…!
Limitations of Dynamic Programming
Although, Dynamic Programming is one of the most popular optimisation techniques, it is applicable only when –
- Subproblems form an optimal substructure.
- Subproblems overlap or repeat themselves.
If these conditions don’t meet, Dynamic Programming will only add overheads to the algorithm. For example, do you think applying memoisation to Merge Sort will speed up the algorithm…? No..! This is because the sub problems are disjoint in nature. Such situations draw a line in the sand for Dynamic Programming.
So, it is up to you that you feel if Dynamic Programming, or Divide-and-Conquer or Greedy approach is correct for the given problem. These three can get real confusing. And the best way to deal with it is by practice. And this is what we will be doing in all the posts to come, related to Dynamic Programming. We will take up some classical DP problems and solve them. This post was to get you started with Dynamic Programming. I know it is a very very long post, in fact this is the longest of mine so far…! Thanks for being very patient with me..! I hope my post has helped you, if it did, let me know by commenting…! Keep practising… Happy Coding…! 🙂
6 thoughts on “Dynamic Programming – Introduction and Fibonacci Numbers”
Nice post bro. Please keep going!
Thank you…! 🙂
Hey, are you planning to continue the DP tutorials?
Yeah… I will resume DP tutorials after a few more posts… 🙂
do you have any video lectures regarding the given tutorial ??
Yes, the Introduction to Algorithms course of MIT OpenCourseware explains this concept… Here’s the link to the YouTube playlist… Dynamic Programming is the 19th video… It’s a great resource for a lot more algorithms too! 🙂